FirstMM Object Data
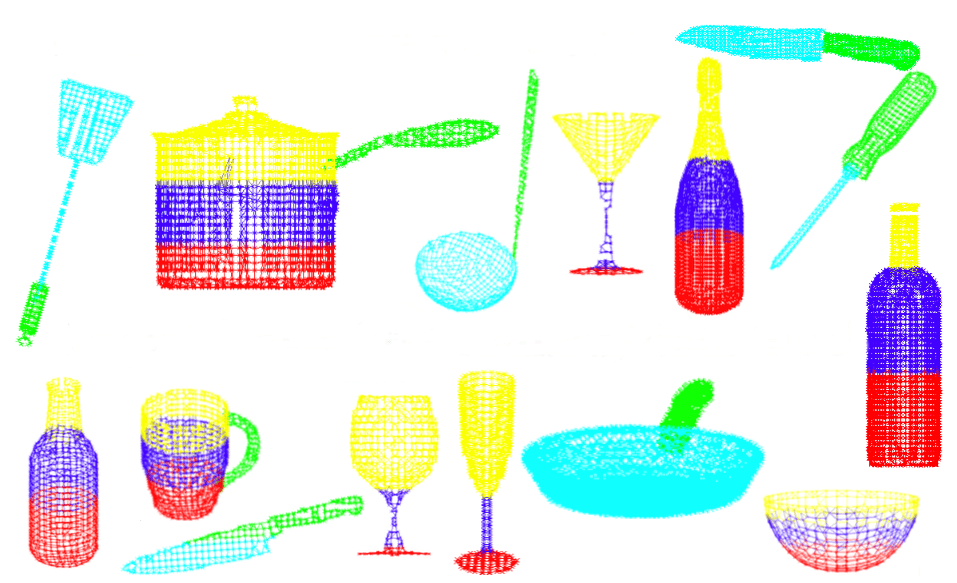
3D point cloud data of various household objects for (semantic and graph-based) object category prediction.
Download HERE. If you use this dataset, please cite the following paper:
Graph Kernels for Object Category Prediction in Task-Dependent Robot Grasping. M. Neumann, P. Moreno, L. An- tanas, R. Garnett, and K. Kersting. In Proceedings of the Eleventh Workshop on Mining and Learning with Graphs (MLG–2013), Chicago, US, 2013.
Populated Places Data
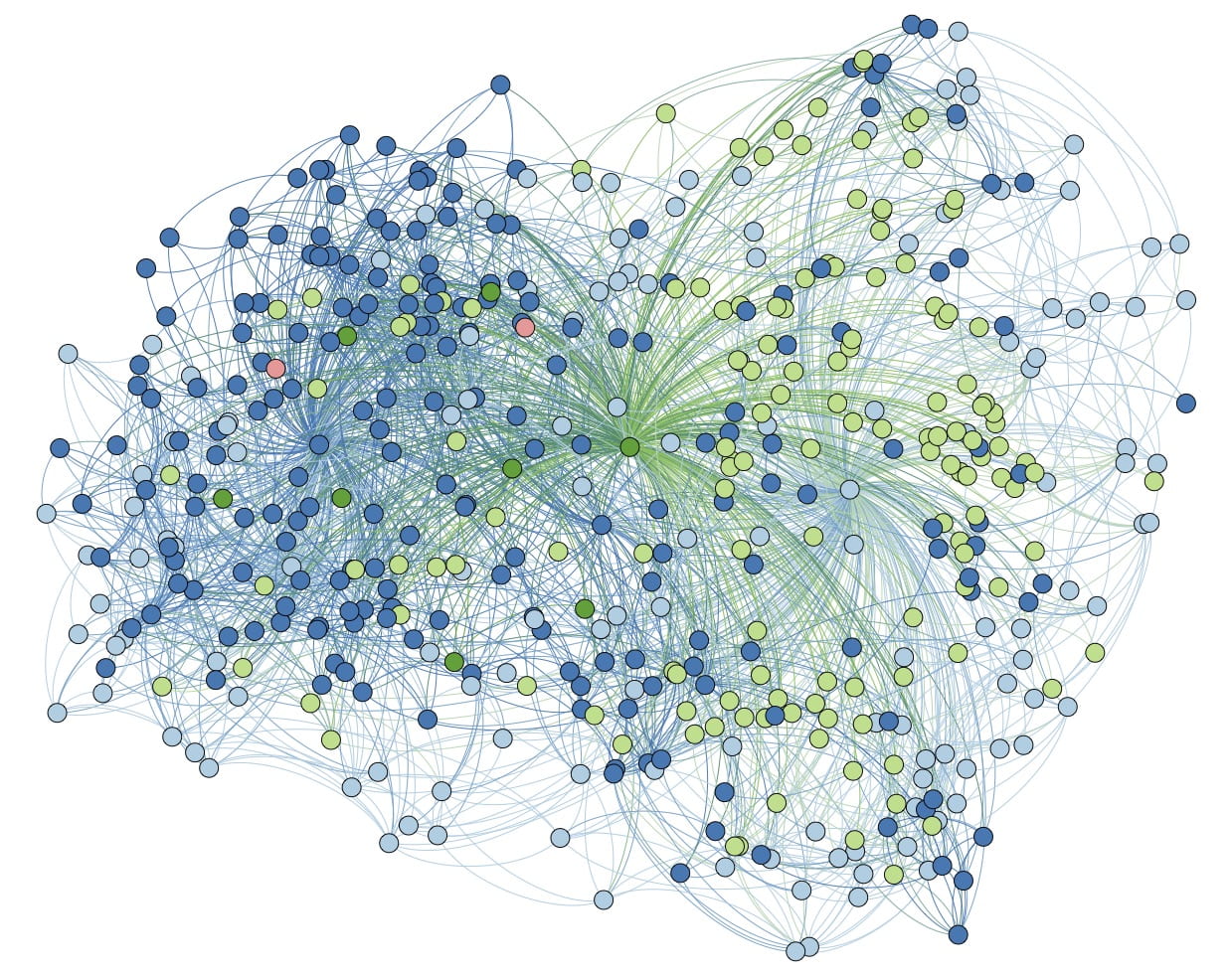
The populated places graph is a subgraph of a labeled graph built from concepts in the DBpedia ontology marked as “populated places.” Each concept is a node in our graph and is backed by a Wikipedia page. We added an undirected edge between two places if one of their corresponding Wikipedia pages links to the other. In the DBpedia ontology populated places are divided into five classes: country, administrative regions, city, town, and village. This graph does not necessarily exhibit homophily; for example, villages (approximately half the dataset) are much more likely to link to countries than to other villages. We built a graph with 1000, 3000, 5000, and 100000 nodes by taking a breadth-first search from first node “Alabama.” We also provie a graph extractor implemented in MATLAB. Download HERE. If you use this dataset, please cite the following paper:
Coinciding Walk Kernels: Parallel Absorbing Random Walks for Learning with Graphs and Few Labels.
M Neumann, R Garnett, K Kersting. In Asian conference on machine learning (ACML-13), pp. 357–372.
Benchmark Data Sets for Graph Kernels

This graph database contains collected benchmark data sets for the evaluation of graph kernels. The data sets were collected by Kristian Kersting, Nils M. Kriege, Christopher Morris, Petra Mutzel, and Marion Neumann with partial support of the German Science Foundation (DFG) within the Collaborative Research Center SFB 876 “Providing Information by Resource-Constrained Data Analysis”, project A6“Resource-efficient Graph Mining”.
If you use a dataset from this repository, please cite the following paper:
TUDataset: A collection of benchmark datasets for learning with graphs
Christopher Morris, Nils M. Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, Marion Neumann. In ICML 2020 workshop “Graph Representation Learning and Beyond (GRL+)”